[译]PyTorch 2.x
PyTorch 2.x: faster, more pythonic and as dynamic as ever
目录
- 目录
- 概述
- PyTorch 2.x:更快、更Pythonic、一如既往地动态
- 设计动机
- 技术概览
- 用户体验
- 分布式
- 开发者/供应商体验
- 结语
- 使用 PyTorch 2.0 加速 Hugging Face 和 TIMM 模型
- 环境要求
- 快速入门
- 常见问题解答 (FAQ)
- 工程师面对面:2.0 在线问答系列
- 观看 PyTorch 大会演讲
概述
PyTorch 2.0 是我们迈向下一代 2 系列 PyTorch 版本的第一步。在过去的几年里,我们从 PyTorch 1.0 不断创新迭代到最新的 1.13 版本,并加入了新成立的 PyTorch Foundation,成为 Linux Foundation 的一部分。
PyTorch 最大的优势除了我们出色的社区之外,还在于其一流的 Python 集成、命令式编程风格以及 API 的简洁性和可选择性。PyTorch 2.0 提供了相同的 eager 模式开发体验,同时在底层编译器层面从根本上改变并大幅增强了 PyTorch 的运行方式,提升了性能以及对动态形状和分布式的支持。
下文中你将找到所有需要的信息,包括 PyTorch 2.0 是什么、发展方向,以及如何今天就开始使用(教程、环境要求、模型、常见问题等)。我们还有很多需要学习和开发的东西,期待社区的反馈和贡献,让 2 系列变得更好。感谢所有为 1 系列成功做出贡献的人。
PyTorch 2.x:更快、更Pythonic、一如既往地动态
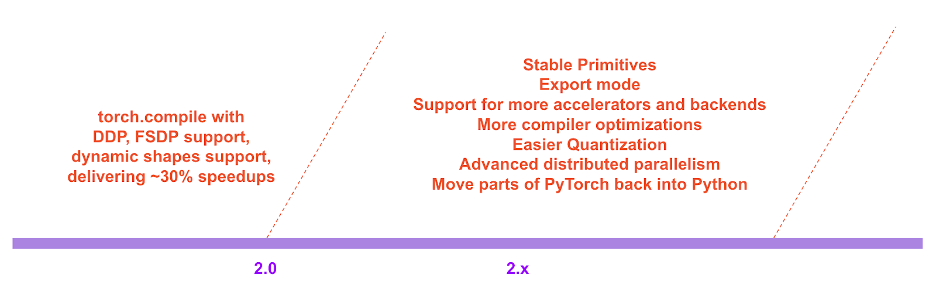
今天,我们宣布推出 torch.compile——这项特性将 PyTorch 性能推向新的高度,并开始将 PyTorch 的部分实现从 C++ 重新移回 Python。我们相信这是 PyTorch 的一个重大新方向,因此将其命名为 2.0。torch.compile 是一个完全附加(且可选)的特性,因此 2.0 在定义上是 100% 向后兼容的。
支撑 torch.compile 的是以下新技术 —— TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor。
- TorchDynamo 利用 Python Frame Evaluation Hooks 安全地捕获 PyTorch 程序,这是一项重要创新,源自我们 5 年来在安全图捕获方面的研发。
- AOTAutograd 重载了 PyTorch 的 autograd 引擎,作为一个追踪式自动微分工具,用于生成提前编译的反向图。
- PrimTorch 将约 2000+ 个 PyTorch 算子规约到一套封闭的约 250 个基础算子,开发者可以基于此构建完整的 PyTorch 后端,大幅降低了编写 PyTorch 特性或后端的门槛。
- TorchInductor 是一个深度学习编译器,为多种加速器和后端生成快速代码。对于 NVIDIA 和 AMD GPU,它使用 OpenAI Triton 作为关键构建块。
TorchDynamo、AOTAutograd、PrimTorch 和 TorchInductor 均使用 Python 编写,并支持动态形状(即能够输入不同尺寸的张量而无需重新编译),使得它们灵活、易于修改,并降低了开发者和供应商的入门门槛。
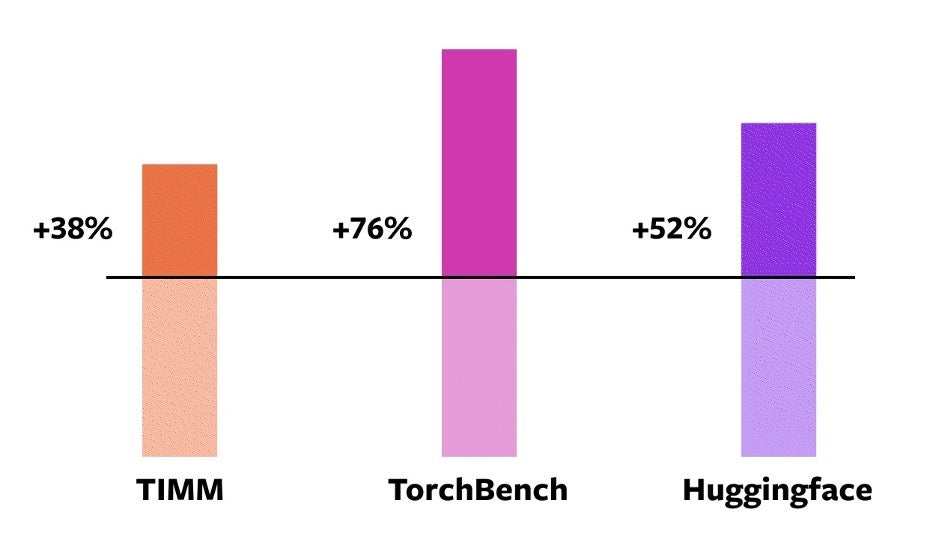
为验证这些技术,我们在不同机器学习领域使用了 163 个开源模型进行测试,涵盖了图像分类、目标检测、图像生成,以及语言模型、问答、序列分类等各类 NLP 任务,还包括推荐系统和强化学习。我们将基准测试分为三类:
- 来自 HuggingFace Transformers 的 46 个模型
- 来自 TIMM 的 61 个模型:由 Ross Wightman 维护的 PyTorch 图像模型集合
- 来自 TorchBench 的 56 个模型:精心策划的来自 GitHub 的流行代码库集合
我们未对这些开源模型做任何修改,仅添加了一行 torch.compile 调用进行包装。
接着检测了速度提升并验证了精度。由于加速效果依赖数据类型,我们分别测量了 float32 和自动混合精度(AMP)下的加速效果。我们报告的加权平均加速比为 0.75 × AMP + 0.25 × float32,因为在实践中 AMP 更为常见。
在这 163 个开源模型中,torch.compile 在 93% 的情况下正常工作,在 NVIDIA A100 GPU 上训练时速度提升 43%。在 Float32 精度下,平均速度提升 21%;在 AMP 精度下,平均速度提升 51%。
注意事项: 在桌面级 GPU(如 NVIDIA 3090)上,加速效果低于服务器级 GPU(如 A100)。目前,默认后端 TorchInductor 支持 CPU 以及 NVIDIA Volta 和 Ampere GPU,暂不支持其他 GPU、xPU 或旧款 NVIDIA GPU。
torch.compile 在 NVIDIA A100 GPU 上相比 eager 模式的加速比
立即体验: torch.compile 处于早期开发阶段。从今天起,可以在 nightly 二进制版本中试用。我们预计在 2023 年 3 月初发布第一个稳定的 2.0 版本。
在 PyTorch 2.x 的路线图中,我们希望不断推进编译模式的性能和可扩展性。部分工作正在进行中,我们在今天的大会上也有所提及;部分工作尚未启动;还有部分工作是我们希望看到但由于资源限制无法亲自完成的。如果有兴趣贡献,欢迎参加本月开始的 “工程师面对面:2.0 在线问答系列”(详情见文末)和/或通过 GitHub / Forums 与我们交流。
用户评价
以下是部分 PyTorch 用户对新方向的评价:
Sylvain Gugger,HuggingFace transformers 的主要维护者:
“只需添加一行代码,PyTorch 2.0 就能在训练 Transformers 模型时带来 1.5x 到 2.x 倍的加速,这是自混合精度训练推出以来最令人兴奋的事情!”
Ross Wightman,TIMM 的主要维护者(PyTorch 生态中最大的视觉模型库之一):
“无需任何代码修改,就能在大多数 TIMM 模型上直接运行推理和训练负载。”
Luca Antiga,Lightning AI 的 CTO,PyTorch Lightning 的主要维护者之一:
“PyTorch 2.0 代表了深度学习框架的未来。无需用户介入即可捕获 PyTorch 程序,并获得巨大的设备端加速和程序可操作能力,为 AI 开发者开启了一个全新的维度。”
设计动机
我们 PyTorch 的理念始终是将灵活性和可修改性放在首位,性能紧随其后。我们的目标是:
- 高性性能的 eager 执行
- Pythonic 的内部实现
- 良好的分布式、自动微分、数据加载、加速器等抽象
自 2017 年推出 PyTorch 以来,硬件加速器(如 GPU)的计算能力提升了约 15 倍,内存访问速度也提升了约 2 倍。为了保持 eager 执行的高性能,我们不得不将 PyTorch 内部大量代码迁移至 C++,但这降低了可修改性,增加了代码贡献的入门门槛。
从一开始,我们就知道 eager 执行的性能存在上限。2017 年 7 月,我们启动了第一个 PyTorch 编译器研究项目。编译器需要让 PyTorch 程序变快,但不能以牺牲 PyTorch 的使用体验为代价。关键的准则是保留特定类型的灵活性——即对动态形状和动态程序的支持,这些是研究者在探索各阶段中所需要的。
技术概览
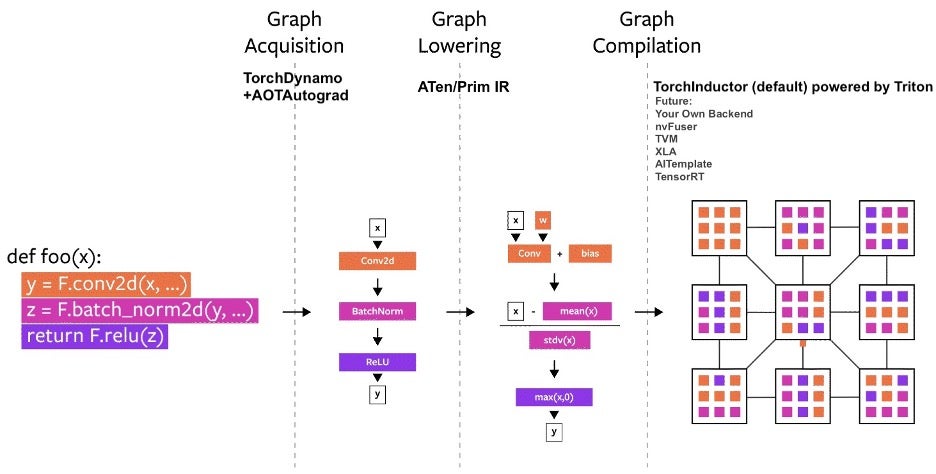
多年来,我们在 PyTorch 内部构建了多个编译器项目。可将编译器拆分为三个部分:
- 图捕获(graph acquisition)
- 图降级(graph lowering)
- 图编译(graph compilation)
其中,图捕获是构建 PyTorch 编译器时最具挑战性的部分。
在过去 5 年中,我们构建了 torch.jit.trace、TorchScript、FX tracing 和 Lazy Tensors,但没有一个能够完全满足我们的需求。有的灵活但不够快,有的快但不够灵活,还有的既不快也不灵活;有些用户体验不佳(例如”静默出错”)。虽然 TorchScript 显示出一定潜力,但它需要对代码及其依赖进行大量修改,这使得许多 PyTorch 用户无法接受。
PyTorch 编译过程
TorchDynamo:可靠且快速地捕获计算图
今年早些时候,我们开始研究 TorchDynamo,这种方法利用 PEP-0523 引入的 CPython Frame Evaluation API。我们采用了数据驱动的方式验证其在图捕获上的有效性——使用 7000+ 个基于 PyTorch 的 GitHub 项目作为验证集。TorchScript 等方法甚至在 50% 的情况下都难以成功获取计算图,且往往开销巨大,而 TorchDynamo 在 99% 的情况下 都能正确、安全、以可忽略的开销捕获计算图——且无需对原始代码做任何修改。这是我们多年来在灵活性和速度方面苦苦挣扎后,终于突破的壁垒。
TorchInductor:基于define-by-run IR的快速代码生成
对于 PyTorch 2.0 的新编译器后端,我们从用户编写高性能自定义 kernel 的方式中汲取了灵感:越来越多的用户使用 Triton 语言。我们也希望有一个与 PyTorch eager 模式使用相似抽象层次、并且足够通用的编译器后端,以支持 PyTorch 中的广泛功能。TorchInductor 使用 Pythonic 的 define-by-run 循环级 IR,将 PyTorch 模型自动映射为 GPU 上的 Triton 代码和 CPU 上的 C++/OpenMP 代码。TorchInductor 的核心循环级 IR 仅包含约 50 个算子,且完全由 Python 实现,使其易于修改和扩展。
AOTAutograd:利用Autograd进行提前编译图
对于 PyTorch 2.0,我们知道需要加速训练过程。因此,不仅需要捕获用户层面的代码,还需要捕获反向传播过程。同时,我们希望重用现有的经过实战检验的 PyTorch 自动微分系统。AOTAutograd 利用 PyTorch 的 torch_dispatch 扩展机制来追踪 Autograd 引擎,从而可以”提前”(ahead-of-time)捕获反向传播过程,进而可以使用 TorchInductor 同时加速前向和反向传播。
PrimTorch:稳定的基础算子集
为 PyTorch 编写后端极具挑战性:PyTorch 拥有 1200+ 个算子,如果考虑每个算子的各种重载,则超过 2000 个。
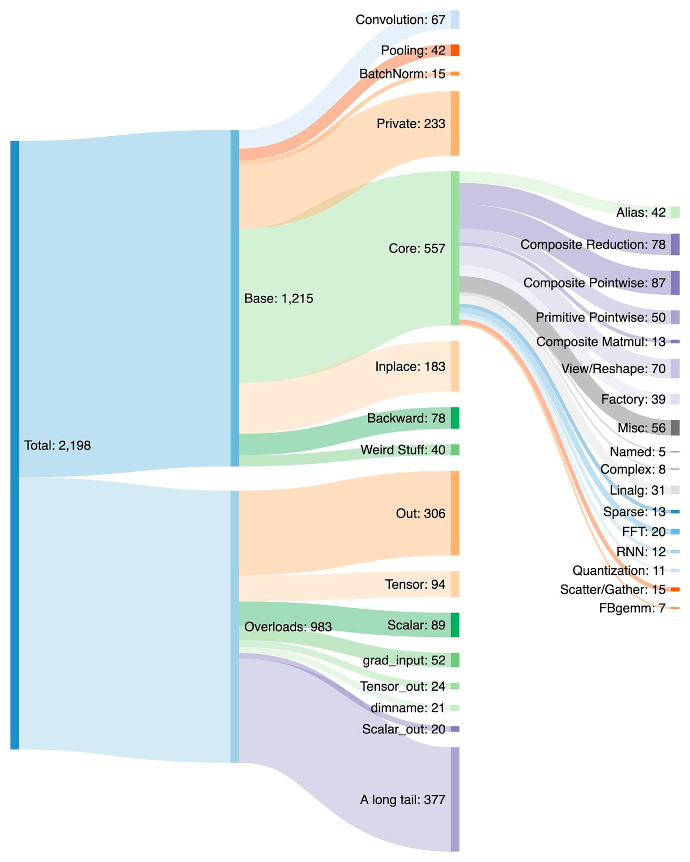
2000+ PyTorch 算子的构成
因此,编写后端或跨领域特性变得异常繁重。在 PrimTorch 项目中,我们正在定义更小且稳定的算子集,PyTorch 程序可以被一致地降级到这些算子集。我们计划定义两个算子集:
- Prim 算子:约 250 个,较为底层。适合编译器使用,因为足够底层,需要通过融合来获得良好性能。
- ATen 算子:约 750 个规范算子,适合按原样导出。适用于已经集成在 ATen 层面的后端,或者不需要通过更低层算子集进行编译优化来恢复性能的后端。
我们将在下文的”开发者/供应商体验”部分进一步讨论此话题。
用户体验
我们引入了一个简单的函数 torch.compile,它封装模型并返回一个编译后的模型。
1 | compiled_model = torch.compile(model) |
此 compiled_model 持有模型的引用,并将 forward 函数编译为更优化的版本。编译模型时,提供了若干参数进行调优:
1 | def torch.compile(model: Callable, |
- mode 指定编译器在编译时应优化什么。
- 默认模式(default)是一个预设,在不过多延长编译时间且不额外消耗内存的前提下高效编译。
- 其他模式如
reduce-overhead可以大幅减少框架开销,但会消耗少量额外内存。max-autotune编译时间较长,力求生成最快的代码。
- dynamic 指定是否启用动态形状的代码路径。某些编译器优化无法应用于动态形状的程序。明确指定程序是动态形状还是静态形状,将帮助编译器生成更好的优化代码。
- fullgraph 类似于 Numba 的
nopython。将整个程序编译为单个计算图,如果无法做到则报错解释原因。大多数用户无需使用此模式。如果你对性能有极致追求,可以尝试使用。 - backend 指定使用哪个编译器后端。默认使用 TorchInductor,但也有其他可选后端。

编译体验旨在默认模式下提供最大的收益和最高的灵活性。以下是在每种模式下的心智模型,帮助理解你在每种模式下的预期效果。
接下来,看一个完整的示例——编译一个真实模型并使用随机数据运行:
1 | import torch |
首次运行 compiled_model(x) 时会编译模型,因此耗时较长,后续运行速度会很快。
编译模式
编译器提供了若干预设,以不同的方式调优编译后的模型。你可能正在运行一个小模型,框架开销是瓶颈;也可能在运行一个勉强能放进内存的大模型。根据不同需求,可以选择不同的模式。
1 | # API 尚未最终确定 |
读取与更新属性
模型属性的访问与 eager 模式下一致。你可以像平时一样访问或修改模型属性(如 model.conv1.weight),这在代码正确性方面是完全安全的。TorchDynamo 会在代码中插入”守卫”(guards)来检查假设是否仍然有效。如果属性以特定方式发生变化,TorchDynamo 会自动按需重新编译。
1 | # optimized_model 与 model 类似,可以自由访问和修改属性 |
钩子(Hooks)
Module 和 Tensor 的钩子目前未完全支持,但随着开发的推进,最终将实现完整功能。
序列化
你可以序列化 optimized_model 或 model 的 state-dict,它们指向相同的参数和状态,因此是等价的。
1 | torch.save(optimized_model.state_dict(), "foo.pt") |
目前不能直接序列化 optimized_model 对象本身。如果需要直接保存对象,请保存 model。
1 | torch.save(optimized_model, "foo.pt") # 报错 |
推理与导出
在模型推理中,使用 torch.compile 生成编译后的模型后,在实际模型服务之前先执行一些预热步骤,这有助于减轻初始推理时的延迟毛刺。
此外,我们将引入一个名为 torch.export 的模式,它会仔细导出整个模型及守卫基础设施,适用于需要保证可预测延迟的环境。注意,torch.export 需要对代码进行修改,特别是存在数据依赖的控制流时。
1 | # API 尚未最终确定 |
此功能处于早期开发阶段。更多细节请关注 PyTorch 大会上有关 Export Path 的演讲。你也可以在我们本月开始的”工程师面对面:2.0 在线问答系列”中参与讨论(详情见文末)。
问题调试
编译模式不够透明且难以调试,你可能会遇到以下问题:
- 为什么我的程序在编译模式下崩溃?
- 编译模式的精度是否与 Eager 模式一致?
- 为什么没有看到速度提升?
如果编译模式出现错误、崩溃或与 Eager 模式的输出不一致(超出机器精度范围),大概率不是你的代码问题。然而,定位导致 bug 的具体代码片段仍然很有用。
为了辅助调试和复现,我们创建了多种工具和日志记录功能,其中最突出的是:The Minifier(压缩器)。
Minifier 会自动将你遇到的问题缩减为一段小代码片段,该代码片段可以复现原始问题。你可以将缩减后的代码提交为 GitHub issue,帮助开发团队轻松快速地解决问题。
如果没有看到预期的加速效果,可以使用 torch._dynamo.explain 工具来了解代码的哪些部分触发了”图断裂”(graph breaks)。图断裂通常会阻碍编译器对代码的加速,减少图断裂的数量大概率能提速(但有一定递减报酬的上限)。
更多内容请参阅我们的问题排查指南。
动态形状
在考虑支持 PyTorch 代码的通用性时,一个关键需求是支持动态形状,即允许模型接收不同大小的张量,而不会在每次形状变化时触发重新编译。
目前,对动态形状的支持是有限的,并且在快速推进中。它将在稳定版本中实现完整功能,当前通过 dynamic=True 参数启用,我们在一个特性分支(symbolic-shapes)上取得了更多进展,已成功在 TorchInductor 上以完全符号化形状训练了 BERT_pytorch。对于动态形状的推理,覆盖率更高。以下看一个动态形状常见场景——语言模型的文本生成。
可以看到,即使形状从 4 动态变化到 256,编译模式始终比 eager 模式快 40%。如果不支持动态形状,常见的变通方法是将输入填充到最近的 2 的幂次方。但从下图可见,这种方法会带来显著的性能开销,且编译时间更长。此外,填充操作有时并不那么容易做得正确。
通过在 PyTorch 2.0 的编译模式下支持动态形状,我们可以同时获得最佳性能和便捷的使用体验。
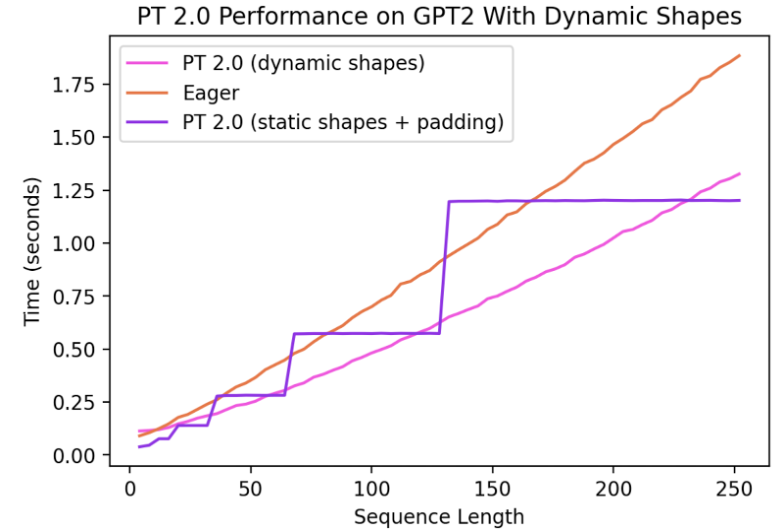
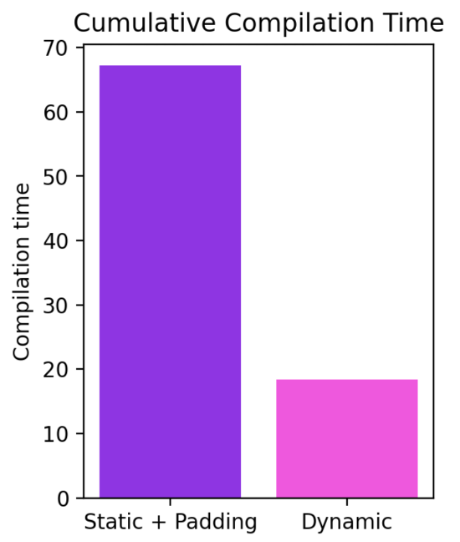
当前的工作进展非常快,在落地基础架构改进的过程中,我们可能会暂时让部分模型性能有退化。关于动态形状的最新进展可以在此查看。
分布式
总体而言,torch.distributed 的两个主要分布式封装器在编译模式下运行良好。
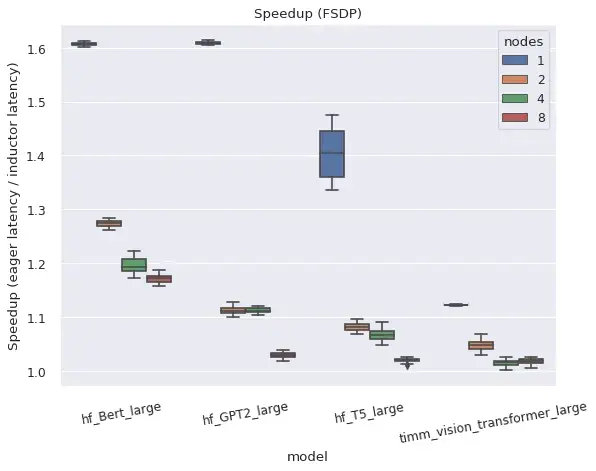
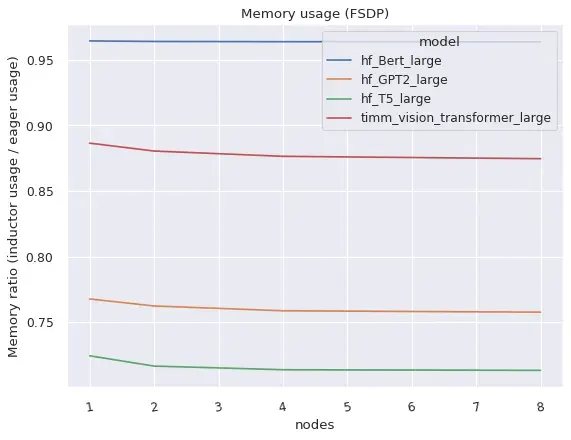
DistributedDataParallel (DDP) 和 FullyShardedDataParallel (FSDP) 均可在编译模式下工作,相比 Eager 模式提供了更好的性能及更优的显存利用率,但也存在一些限制与注意事项。
AMP 精度下的加速比
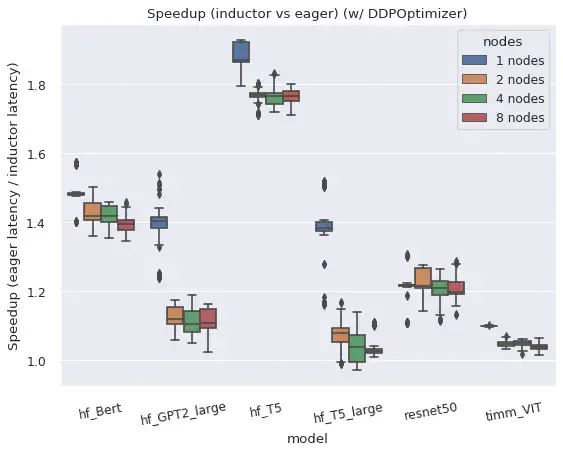
左图:FSDP 在编译模式下相比 eager 模式的加速比(AMP 精度)。右图:编译模式下的 FSDP 比 eager 模式占用明显更少的显存
DistributedDataParallel (DDP)
DDP 依赖将 AllReduce 通信与反向计算重叠,并将较小的逐层 AllReduce 操作分组到”桶”中以提升效率。当与 DDP 直接组合使用时,TorchDynamo 编译的 AOTAutograd 函数会阻止通信重叠,但通过为每个”桶”编译独立的子图,并允许通信操作在子图外部及之间进行,性能得以恢复。DDP 在编译模式下还需要 static_graph=False。关于 DDP + TorchDynamo 的方法及结果,请参阅这篇文章。
FullyShardedDataParallel (FSDP)
FSDP 本身是 PyTorch 的”beta” 特性,其系统复杂度高于 DDP,因为可以调整哪些子模块被封装,且配置选项更多。如果配置了 use_original_params=True 标志,FSDP 可以在多种流行模型上与 TorchDynamo 和 TorchInductor 兼容。目前某些特定模型或配置可能存在兼容性问题,我们会积极改进;如果提交 GitHub issue,特定模型可被优先处理。
用户可以指定 auto_wrap_policy 参数来指示哪些子模块应一起封装在一个 FSDP 实例中用于状态切片,也可以手动将子模块封装在 FSDP 实例中。例如,许多 Transformer 模型在将每个”transformer block”封装在独立的 FSDP 实例中时效果很好,这样一次只需物化一个 transformer block 的完整状态。Dynamo 会在每个 FSDP 实例的边界插入图断裂(graph break),使得前向(及反向)中的通信操作能够在图外部与计算并行执行。
如果 FSDP 没有将子模块封装在独立实例中,则会退化为类似于 DDP 的行为,但没有 bucketing。因此,所有梯度在一次操作中规约,即使在 Eager 模式下也无法实现计算/通信重叠。此配置仅测试了功能兼容性,未进行性能验证。
开发者/供应商体验
在 PyTorch 2.0 中,我们希望简化后端(编译器)的集成体验。为此,我们专注于减少算子数量和简化算子语义,以降低搭建 PyTorch 后端的门槛。
PT2 技术栈的图示如下:
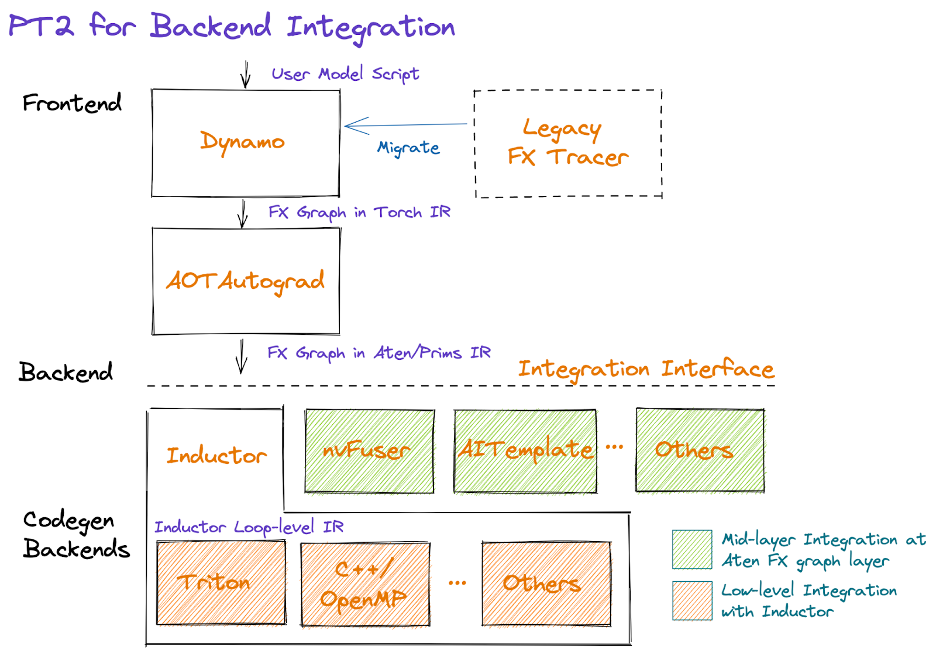
从图的中间部分开始:AOTAutograd 以前置方式动态捕获自动微分逻辑,生成 FX 图格式的前向和反向算子图。
我们提供了一套经过验证的算子分解(即用其他算子实现某个算子的方式),可用于减少后端需要实现的算子数量。我们还通过一种称为 函数化(functionalization) 的过程——即选择性地重写包括 mutation 和 view 在内的复杂 PyTorch 逻辑——以及保证算子元数据信息(如形状传播公式),来简化 PyTorch 算子语义。这项工作正在积极进行中;我们的目标是提供一套约 250 个具有简化语义的 基础 和 稳定 算子集——称为 PrimTorch——供应商可以利用(即 opt-in)来简化集成。
在减少和简化算子集之后,后端可以选择在 Dynamo 层(即中间层,紧接在 AOTAutograd 之后)或 Inductor 层(较低层)进行集成。下文描述了在做此选择时需要考虑的一些因素,以及未来关于后端混合的工作。
Dynamo 后端
拥有现有编译器技术栈的供应商可能会发现,作为 TorchDynamo 后端进行集成最为便捷——接收以 ATen/Prims IR 表达的 FX 图。需要注意的是,无论是训练还是推理,集成都发生在 AOTAutograd 之后,因为我们目前将分解作为 AOTAutograd 的一部分,在面向推理时只需跳过反向传播相关的步骤。
Inductor 后端
供应商也可以将其后端直接集成到 Inductor 中。Inductor 接收由 AOTAutograd 生成的图(由 ATen/Prim 操作组成),并将它们进一步降级为循环级 IR。目前,Inductor 为 pointwise、reduction、scatter/gather 和 window 等操作提供了到其循环级 IR 的降级实现。此外,Inductor 创建融合组(fusion groups)、进行索引简化、维度折叠,并调优循环迭代顺序,以支持高效代码生成。供应商可以通过提供从循环级 IR 到硬件特定代码的映射来进行集成。当前,Inductor 有两个后端:(1) 生成多线程 CPU 代码的 C++ 后端,(2) 生成高性能 GPU 代码的 Triton 后端。这些 Inductor 后端可以作为替代后端的参考实现。
混合后端接口(即将推出)
我们构建了将 FX 图划分为包含某后端支持算子的子图并让其余部分在 Eager 模式下执行的工具。这些工具可扩展用于支持”混合后端”,即可配置图的哪些部分在哪个后端上运行。然而,目前尚未有稳定的接口或契约用于后端暴露其算子支持范围、对算子模式的偏好等。此项工作仍在进行中,欢迎早期采纳者提出反馈。
结语
我们对 PyTorch 2.0 及未来的方向感到无比兴奋。通往最终 2.0 版本的道路注定崎岖不平,但请尽早加入我们这一旅程。如果你有兴趣深入学习或为编译器做贡献,请继续阅读下文,其中包含更多关于如何入门的信息(如教程、基准测试、模型、常见问题),以及本月开始的 “工程师面对面:2.0 在线问答系列”。其他资源包括:
使用 PyTorch 2.0 加速 Hugging Face 和 TIMM 模型
作者:Mark Saroufim
torch.compile() 让你能够轻松尝试不同的编译器后端,通过一行装饰器 torch.compile() 即可让 PyTorch 代码更快。它可以直接覆盖 nn.Module,作为 torch.jit.script() 的替代方案,但无需修改任何源代码。我们预计这一行代码的改动,就能为你在绝大多数已在运行的模型上带来 30% 至 2 倍的训练速度提升。
1 | opt_module = torch.compile(module) |
torch.compile 支持任意 PyTorch 代码、控制流、mutation,并带有对动态形状的实验性支持。我们对此充满热情,因此将其称为 PyTorch 2.0。
这次发布的不同之处在于,我们已对一些最流行的开源 PyTorch 模型进行了基准测试,并取得了 30% 到 2 倍不等的显著加速 https://github.com/pytorch/torchdynamo/issues/681。
这里没有任何取巧之处——我们只是直接 pip 安装了流行的库,如 HuggingFace Transformers、Accelerate 和 TIMM,然后对其调用 torch.compile(),仅此而已。
同时获得性能和便利性并不常见,但这正是核心团队对 PyTorch 2.0 如此兴奋的原因。
环境要求
GPU(更新代的 GPU 将获得显著更好的性能)
1 | pip3 install numpy --pre torch --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117 |
CPU
1 | pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cpu |
可选:验证安装
1 | git clone https://github.com/pytorch/pytorch |
可选:Docker 安装
我们还提供了包含所有依赖的 PyTorch Nightly Docker 镜像:
1 | docker pull ghcr.io/pytorch/pytorch-nightly |
对于临时实验,确保容器可以访问所有 GPU:
1 | docker run --gpus all -it ghcr.io/pytorch/pytorch-nightly:latest /bin/bash |
快速入门
请阅读 Mark Saroufim 的完整博客文章,他通过教程和真实模型引导你今天就体验 PyTorch 2.0。
我们构建 PyTorch 的目标是开发一个广度优先(breadth-first)的编译器,能够加速大多数人们在开源社区中实际运行的模型。Hugging Face Hub 最终证明是我们极其有价值的基准测试工具,确保我们做的任何优化确实能够加速人们想要运行的模型。
博客教程将向你展示如何精确复现这些加速效果,让你和我们一样对 PyTorch 2.0 感到兴奋。所以请赶紧试试 PyTorch 2.0,享受这份免费的性能提升吧。如果你没有看到预期的加速,请在 GitHub 上提交 issue,我们会确保你的模型得到支持。
毕竟,除非你的模型真正跑得更快,否则我们不能宣称自己创造了一个”广度优先”的编译器。
常见问题解答 (FAQ)
什么是 PT 2.0?
2.0 是最新的 PyTorch 版本。PyTorch 2.0 提供了相同的 Eager 模式开发体验,同时通过torch.compile新增了编译模式。该编译模式有望在训练和推理过程中加速你的模型。为什么是 2.0 而不是 1.14?
PyTorch 2.0 就是原计划中的 1.14。我们发布了多项重大新特性,这些特性将在本质上改变你使用 PyTorch 的方式,因此我们将其命名为 2.0。如何安装 2.0?有什么额外要求吗?
安装最新的 Nightly 版本:
CUDA 11.8
1
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118
CUDA 11.7
1
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117
CPU
1
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cpu
2.0 代码是否向后兼容 1.X?
是的,使用 2.0 无需修改 PyTorch 工作流程。一行代码model = torch.compile(model)即可使用 2.0 技术栈优化模型,并与其余 PyTorch 代码顺利运行。这是完全可选的功能,你并非一定要使用新的编译器。2.0 是默认启用的吗?
2.0 是版本的名称,torch.compile是 2.0 中发布的新特性,需要显式调用。如何从 PT1.X 代码迁移到 PT2.0?
你的代码应当无需任何迁移即可直接运行。如果想使用 2.0 中引入的新编译模式特性,可以通过一个代码优化模型:model = torch.compile(model)。虽然加速主要体现在训练阶段,但若模型在编译模式下比 Eager 模式更快,同样可以用于推理。
1
2
3
4
5
6
7
8
9
10import torch
def train(model, dataloader):
model = torch.compile(model)
for batch in dataloader:
run_epoch(model, batch)
def infer(model, input):
model = torch.compile(model)
return model(**input)为什么应当使用 PT2.0 而非 PT1.X?
请参考问题 (2) 的答案。在 PyTorch 2.0 中我的代码执行上有什么区别?
默认情况下,PyTorch 2.0 与 PyTorch 1.x 相同,模型在 Eager 模式下运行,即每行 Python 代码逐行执行。在 2.0 中,如果通过
model = torch.compile(model)将模型封装,模型会在执行前经历 3 个步骤:- 图捕获:首先模型被重写为子图块。能够被 TorchDynamo 编译的子图会被”展平”,而其他子图(可能包含流程控制代码或其他未受支持的 Python 构造)将回退到 Eager 模式。
- 图降级:所有 PyTorch 操作分解为针对所选后端的组件 kernel。
- 图编译:kernel 调用相应的低级设备特定操作。
PT2.0 在 PT 基础上新增了哪些组件?
- TorchDynamo 从 Python 字节码生成 FX 图。通过守卫(guards)维护 Eager 模式能力,确保生成的图一直有效(了解更多)。
- AOTAutograd 生成与 TorchDynamo 捕获的前向图对应的反向图(了解更多)。
- PrimTorch 将复杂的 PyTorch 操作分解为更简单、更基础的算子(了解更多)。
- [Backend] 后端集成到 TorchDynamo 中将图编译为可在加速器上运行的 IR。例如,TorchInductor 将图编译为用于 GPU 执行的 Triton 或用于 CPU 执行的 OpenMP(了解更多)。
2.0 目前支持哪些编译器后端?
默认且最完善的后端是 TorchInductor,但 TorchDynamo 拥有一套不断增长的后端列表,可通过调用torchdynamo.list_backends()查看。分布式训练在 2.0 中如何运行?
DDP 和 FSDP 编译模式在 FP32 下可比 Eager 快至 15%,在 AMP 精度下增速高达 80%。PT2.0 做了一些额外优化,确保 DDP 的计算-通信重叠与 Dynamo 的部分图创建良好配合。运行 DDP 时请确保static_graph=False。详情请参阅此处。如何进一步了解 PT2.0 的最新进展?
PyTorch 开发者论坛是了解 2.0 各个组件的最佳场所,你可以直接从核心开发者那里获取信息。我的代码在 2.0 编译模式下反而变慢了,怎么回事?
性能下降最常见的原因是过多的图断裂(graph breaks)。例如,在forward函数中一个看似无害的print语句就会触发图断裂。我们提供了诊断方法——在此查阅。我之前能正常运行的代码在 2.0 编译模式下崩溃了!怎么调试?
以下是一些定位代码失败位置和打印有帮助日志的技巧:https://pytorch.org/docs/stable/torch.compiler_faq.html#why-is-my-code-crashing。
工程师面对面:2.0 在线问答系列
我们将举办一系列在线问答活动,让社区有机会与专家进行深入的提问和交流。全年的完整主题日历请关注后续更新。如果你无法参加:1)活动将被录制以供后续观看;2)你可以参加我们每周五上午 10 点(太平洋标准时间)的开发者基础设施办公时间,地址:https://github.com/pytorch/pytorch/wiki/Dev-Infra-Office-Hours。
点击此处查看日期、时间、描述和链接。
免责声明:请勿在参与在线会议和提交问题时分享个人信息、姓氏或公司名称。
| 主题 | 主持人 |
|---|---|
| 使用 2.0 的全新开发者体验(安装、设置、克隆示例代码、使用 2.0 运行) | Suraj Subramanian (LinkedIn, Twitter) |
| PT2 性能分析与调试 | Bert Maher (LinkedIn, Twitter) |
| 深入探讨 TorchInductor 与 PT 2.0 后端集成 | Natalia Gimelshein, Bin Bao 和 Sherlock Huang |
| 无需 C++ 扩展 PyTorch,以及 functorch:类似 JAX 的可组合函数变换 | Anjali Chourdia (LinkedIn, Twitter) 和 Samantha Andow (LinkedIn, Twitter) |
| 深入探讨 TorchDynamo | Michael Voznesensky (LinkedIn) |
| 重新思考数据加载:TorchData: Datapipes 和 Dataloader2 | Kevin Tse (LinkedIn) |
| 可组合训练(+ torcheval, torchsnapshot) | Ananth Subramaniam |
| 如何以及为何为 PyTorch 贡献代码和教程 | Zain Rizvi (LinkedIn, Twitter), Svetlana Karslioglu (LinkedIn, Twitter) |
| 动态形状与最大批次大小计算 | Edward Yang (Twitter) 和 Elias Ellison |
| PyTorch 2.0 导出:可靠的 PyTorch 完整图捕获 | Michael Suo 和 Yanan Cao (LinkedIn) |
| 基于 DistributedTensor 的 2-D 并行,PyTorch DistributedTensor | Wanchao Liang (LinkedIn, Twitter) 和 Alisson Gusatti Azzolini (LinkedIn) |
| TorchRec 与生产环境中的 FSDP | Dennis van der Staay (LinkedIn), Andrew Gu 和 Rohan Varma (LinkedIn, Twitter) |
| PyTorch 端侧的未来 | Raziel Alvarez Guevara (LinkedIn, Twitter) |
| TorchMultiModal (简介博客, 规模化博客) | Kartikay Khandelwal (LinkedIn, Twitter) |
| BetterTransformers(+ 集成 Hugging Face),模型部署与优化 (博客 1, Github) | Hamid Shojanazeri 和 Mark Saroufim (LinkedIn, Twitter) |
| PT2 与分布式 | Will Constable (LinkedIn) |